GPT-2 from scratch —
understanding attention by writing it
You can pip install transformers and spend years building on top of attention without ever understanding it. So I rebuilt the 124M-parameter GPT-2 stack line-by-line in PyTorch — multi-head attention, GELU, transformer blocks, the whole thing — and pretrained it on a medical textbook. This is what I took away from it.
Using attention is easy. Understanding it isn't.
Every LLM project I've shipped in the last two years has been built on top of a pretrained model — Hugging Face, an API, a quantised weight file. That's the right default for production. It is also the fastest way to spend a career near transformers without ever actually understanding them.
I kept running into this gap. I could describe self-attention in an interview. I could not have written it on a blank page. "Softmax of QKᵀ scaled by √dₖ, times V" is a sentence, not an intuition. So I set a rule for myself: write the whole thing from nn.Module up, no Hugging Face, no copy-paste, and don't move on until I could derive each piece from memory.
This writeup is the condensed version — the parts that changed how I think about transformers, with the actual code from the notebook in the order I wrote it.
Not to train a usable language model (the data is tiny and the compute is a laptop). The goal was to build every piece of the GPT-2 architecture by hand so that when I later fine-tune a real model — MedGemma is next — I know exactly what each layer is doing and why.
A medical textbook, a BPE tokenizer, and a sliding window
The corpus is Medicine PreTest Self-Assessment and Review (14th ed.), extracted from PDF via docling. Medical text is a deliberately awkward domain for a general-purpose tokenizer — plenty of rare words, Latin, dosage notation — which makes it a more honest sanity test than the usual tiny Shakespeare.
Tokenization uses tiktoken with GPT-2's 50,257-token BPE vocabulary. That keeps us drop-in compatible with the real GPT-2 weights if I ever want to warm-start from them later.
The dataset itself is a sliding window over the full token stream. For a sequence of max_length tokens, the target is the same sequence shifted by one — classic next-token prediction. The stride parameter lets you trade overlap for unique samples.
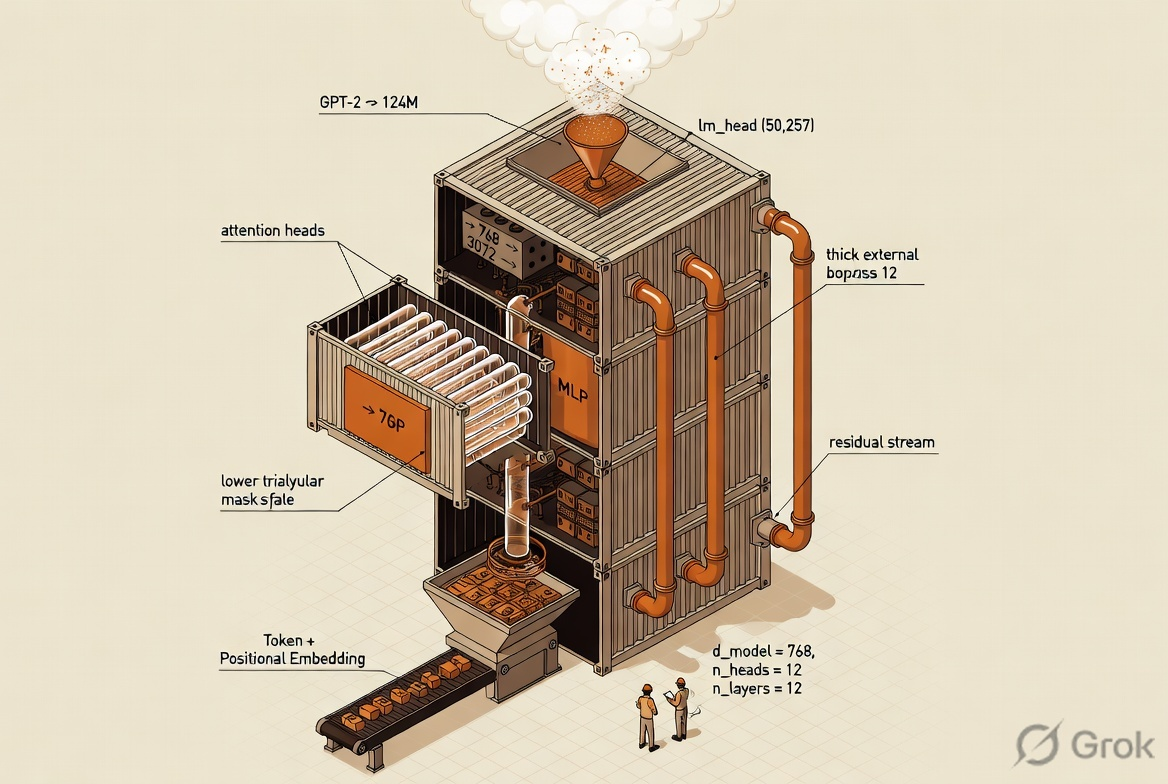
And the GPT-2 base config as a plain dict — this is what gets threaded through every module. The 124M label comes from counting parameters once everything is wired up.
The one piece it's worth writing by hand
Almost every other module in GPT-2 is a one-liner or a stock PyTorch call. Attention is the exception. You can read the formula a hundred times and still not quite feel how the shapes move. So this was the cell I refused to copy from anywhere.
The mental model that finally clicked for me: attention is a soft dictionary lookup. For every token, you compute a query. Every other token has a key (its "label") and a value (its "contents"). You score the query against every key, softmax the scores into weights, and take a weighted sum of the values. That's it. Everything else is plumbing.
Three bits of that plumbing are worth pointing at:
Without it, the dot-product magnitudes grow with dimension, softmax saturates, and gradients die. Dividing by sqrt(head_dim) keeps the logits in a range where softmax still has useful slope. A one-line detail that actually determines whether the model trains at all.
An upper-triangular -inf mask added to the attention logits before softmax. This is what makes GPT "decoder-only": token t can only attend to tokens ≤ t. Without it, you've built an encoder.
The naïve way to do h attention heads is a Python loop. The actual way is a single projection to d_model, then .view() it into (heads, head_dim) and transpose. One matmul, h heads, free parallelism.
After concatenating heads back together, a final Linear(d, d) lets the model mix information across heads. Skipping this makes each head an island. With it, heads can specialise and still inform each other.
If there's one block of code in the whole model that I'd suggest writing by hand at least once, this is it. Everything else rests on top.
LayerNorm, GELU, residuals — the boring parts that make it work
Attention alone does not train. Stack twelve attention layers on top of each other and you get vanishing gradients, unstable activations, and a model that spends most of its time deciding whether to be zero or infinity. The transformer block is the scaffolding that turns attention from a clever idea into something you can actually optimise.
Three ingredients:
The block itself wires those into the two-residual pattern that makes GPT-2 GPT-2 — specifically the pre-LN variant, where LayerNorm is applied before attention and before the MLP, not after. This is different from the original "Attention Is All You Need" post-LN layout and is one of the reasons GPT-2 trains stably at depth.
Stack twelve of them, embed tokens, project to vocab
Once the block is built, the model itself is unreasonably short. It's basically: embed the tokens, add positional embeddings, run them through a stack of twelve identical blocks, layernorm once more, and project to vocabulary logits. No bells, no whistles.
Embeddings (50,257 × 768) ≈ 38.6M. Each of 12 transformer blocks: attention ≈ 2.4M + MLP ≈ 4.7M ≈ 7.1M, times 12 ≈ 85M. Plus output head and norms. Total comes out to ~163M; GPT-2 tied the token embedding with the output head, which is how it's quoted as 124M. That tying is a one-line change and is the easiest "free" parameter-count improvement in the whole stack.
Greedy decoding — the 20-line proof that the shapes work
With an untrained model the output is gibberish, so this is not about quality — it's about closing the loop and proving that a tensor of token IDs can go in, a distribution can come out, and the next token you sample from it can be appended and fed back in. Autoregressive generation in its smallest form:
Swap argmax for top-k or nucleus sampling and you have the inference loop every LLM API you've ever used is doing under the hood. It really is that simple — once everything above actually works.
Five things that only really landed after writing it
Queries ask "what do I need?", keys answer "here's what I am", values carry "here's what I contain". The softmax turns scoring into a differentiable weighted average. Once you hold that picture, every attention variant (cross-attention, grouped-query, sparse) is just a tweak to who-queries-whom.
I used to picture h separate attention modules running in parallel. In reality it's one projection and one matmul, reshaped. This is why scaling heads is essentially free — you're not doing more compute, you're rearranging the same compute.
Delete the x + ... in the transformer block and the model won't train past three layers. The residual stream is what carries the original signal past every attention and MLP, and every layer is really just writing a small update into it.
The original transformer paper put LayerNorm after the residual add. GPT-2 moved it before the attention and MLP. That one change is a big part of why GPT-2 trains stably at 12+ layers where post-LN transformers famously blow up.
Add an upper-triangular -inf before softmax and you've built a decoder. Don't, and you've built an encoder. The architecture is identical; the mask is what commits the model to autoregression.
Stripped of comments, the whole GPT-2 stack is around 150 lines of PyTorch. Every modern LLM architecture is a small, readable perturbation of this. That's a more reassuring fact than it sounds.
MedGemma + tool calling
Writing GPT-2 from scratch was the warm-up. The real goal is to take a modern, medically-pretrained open model — MedGemma — and fine-tune it to reliably call tools: things like a drug-interaction lookup, a dosing calculator, a structured patient-record reader.
Tool calling lives at a specific spot in the stack I now understand concretely: it's a supervised fine-tuning objective on top of next-token prediction, with a strict output format (JSON-ish function calls) that the model has to learn to emit rather than free-form prose. Knowing exactly how the forward pass and the lm_head produce those tokens makes the fine-tuning plan a lot less mysterious.
The pieces I expect to reuse from this project:
1. The tokenizer intuition — what BPE does to medical vocabulary, where it fragments, and why that matters for tool-call output formatting.
2. The loss surface — next-token cross-entropy on formatted tool calls vs prose, and the trade-offs of SFT-only vs DPO for format adherence.
3. The inference loop — constrained decoding, grammar-based sampling, and structured-output techniques all hook into exactly the generate_text_simple shape above.
If you're working on something similar, or have opinions on the MedGemma → tool-calling fine-tune, get in touch.