BosWeigh —
weighing a cow with one photo
A research notebook where I tried to recover a cow's live weight from a single smartphone photograph — using monocular depth estimation, five anatomical keypoints, and a 150-year-old livestock formula. This is the story of what worked, what didn't, and what the numbers are telling me to do next.
Weight is the one number farmers can't measure
Cattle weight drives almost every economic decision a smallholder farmer makes. It sets drug dosing (a dewormer under-dosed by 20% doesn't work; over-dosed, it can kill). It sets the feed ration (under-feeding a 500kg cow the diet of a 350kg cow is the fastest way to destroy her milk yield). It sets the price at livestock markets, the insurance valuation, and — increasingly — whether a bank will lend against the animal.
And yet almost no smallholder farmer actually knows what their cow weighs. A proper livestock weighbridge costs lakhs and needs civil work. A handheld weight tape is close to accurate but is fiddly, assumes a cooperative animal, and most farmers don't own one. Everybody guesses, and everybody guesses low.
While building GauSwastha, I had a regression head that output weight from an image — but it was a black box bolted onto a multi-task model, trained on field labels that were themselves guesses. I wanted to see whether the geometry of the cow, recovered directly from a photo, could get to an answer that was explainable from first principles. That's what BosWeigh is.
Given one ordinary side-view photo of a cow, can we recover enough 3D information — real-world length, girth, curvature — to estimate live weight from a formula rather than from a learned regressor? And if we can, how close does it actually get?
What if monocular depth is good enough now?
The classical approach to measuring an animal from an image needs either a depth sensor (LiDAR, Kinect, structured light) or a fixed reference (a calibration board, a known-size object in-frame). Neither is a realistic ask for a farmer in a shed. So every paper I read worked on rigs the farmer will never buy.
Then in late 2024, Apple released DepthPro — a transformer-based monocular depth estimator that predicts metric depth and focal length from a single RGB image, with no calibration and no reference object. That changed the economics of the problem. If I can get reasonable metric depth from the same image the farmer is already taking, then a phone becomes a 3D scanner.
So the research question collapsed to one thing: is the depth quality good enough that 3D distances computed on top of it are accurate enough to feed into a weight formula?


Five keypoints, one depth map, a bunch of geometry
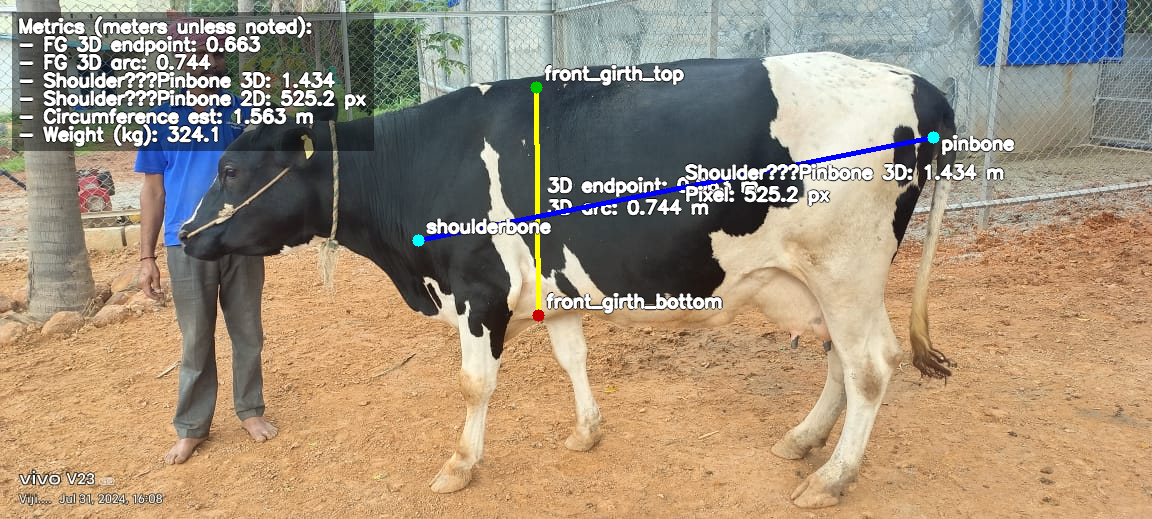
The pipeline is deliberately thin. There are only two learned components: a monocular depth model (frozen, off-the-shelf) and a small YOLOv8 keypoint detector I trained on side-view cow images. Everything else is plain geometry — which means every failure is debuggable.
Run Apple's apple/DepthPro-hf on the raw image. It returns a per-pixel depth map in metres, a predicted focal length, and field of view. No calibration, no rig — we trust the model to recover enough scale to be useful.
A custom keypoint model locates five anatomical landmarks on the cow's side profile: wither, shoulderbone, pinbone, front-girth top, front-girth bottom. These are the same points a vet would find with their hands.
Using the predicted focal length and per-pixel depth, lift each 2D keypoint into a 3D point in camera coordinates. Now the cow lives in metric space — millimetres matter.
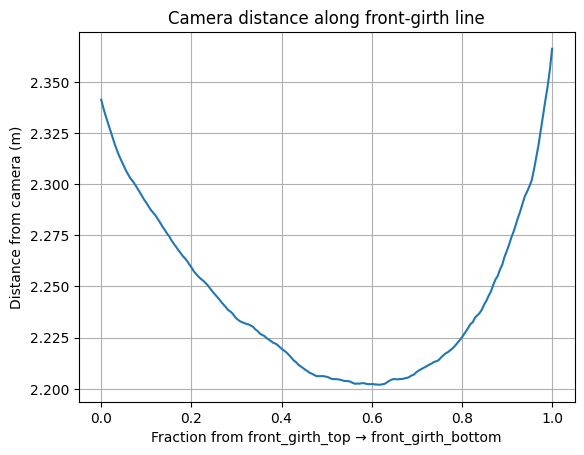
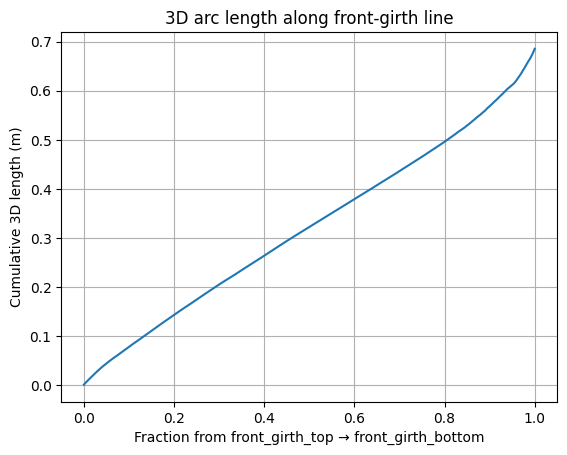
Sample 200 points along each measurement line (e.g. front-girth-top → front-girth-bottom). Read depth at each sample, unproject to 3D, and sum Euclidean distances between consecutive 3D points. This follows the actual curvature of the body instead of cutting a straight line through it.
A single side view only shows half the animal. I build a plane normal to the shoulder-pinbone axis at the girth line, then mirror the visible half-arc around that plane's depth centreline to estimate the full circumference. Crude, but a starting point.
Convert length and girth to inches, plug into weight = (length × girth²) / 660, and report kilograms. The whole chain runs in about 2.5s on CPU.

Straight lines lie; arcs tell the truth
The obvious way to measure "length" on a cow is to take the straight-line 3D distance between shoulder and pinbone. That's what the literature mostly does. It's also wrong — the cow's back is curved, the belly droops, the ribs flare out. A straight line from shoulder to pinbone systematically under-measures.
So instead of one-shot endpoint distances, I sample the line between two keypoints at 200 intermediate pixels, read the depth at each one, unproject to 3D, and sum the consecutive segment lengths. The result is a 3D arc that hugs the body surface — which is what a tape measure does when a vet wraps it around a real cow.
A nineteenth-century equation still runs the industry
The final step is almost comically simple. There is a formula that cattle traders, veterinarians, and agricultural extension officers have used for well over a century — it's in Indian government livestock handbooks, USDA extension leaflets, and pretty much every animal husbandry textbook:
The assumption it encodes is that a cow's body approximates a cylinder whose volume — and therefore mass — scales with the square of the heart girth times the length. It's empirical, but for reasonably-conditioned adult cattle it sits within ~10% of weighbridge numbers when the measurements are taken properly.
So the entire modelling problem reduces to: how well can I measure length and girth from a photo? Everything in the pipeline before this point is in service of getting two numbers right. Weight drops out for free.

The results so far are humbling
I validated the pipeline on 42 cows that had ground-truth tape-measured girth and length, and 49 with ground-truth weight. The short version is that the pipeline runs end-to-end, but it is not yet accurate enough to trust. Here's the honest table from the latest run:
A negative R² means the model does worse than just predicting the mean. That's not a rounding error — it's a signal that the underlying measurement chain is systematically off. The pipeline works mechanically, but the numbers it produces are not yet calibrated to ground truth. This is where the project actually sits today.
The failure modes, in rough order of suspected impact:
DepthPro predicts metric depth, but the absolute scale varies with scene content — especially for outdoor shots with fences and open sky. A 5% depth scale error becomes a ~10% girth error and a ~20% weight error because girth is squared in the formula.
YOLO reports 0.96 confidence on the bounding box, but the individual keypoints can still be 10–20 pixels off. On the girth line that's a couple of centimetres of real-world error; compounded across five keypoints, it drifts the length arc by a lot.
Mirroring the visible half of the cow around a vertical plane assumes perfect left-right symmetry. Real cows sag, lean, and stand on uneven ground. The circumference estimate inherits whatever asymmetry is in the pose.
Tape measurements themselves are noisy — different vets pull the tape at different tensions, and "length" is defined inconsistently across sources. Some of the error I'm seeing is almost certainly in the labels, not the model.
The plan from here
The point of writing this up now, while the numbers are still bad, is to be honest about a research project mid-flight. A few things are queued up:
1. Calibrate DepthPro with an in-frame reference. Even something as simple as asking the farmer to stand a 1m pole next to the animal gives me an absolute scale anchor and should kill most of the depth-scale drift.
2. Retrain the keypoint detector on 10× more data. The current model was trained on a few hundred hand-labelled side views. The cheapest improvement in the whole pipeline is almost certainly more labels — especially across breed, coat colour, and lighting conditions.
3. Replace the symmetry assumption with a learned correction. Once I have weighbridge-paired data, I can fit a small regression from (measured-arc, breed, BCS) → (true girth) that corrects for the asymmetry. That turns the geometry pipeline into a strong prior rather than a final answer.
4. Compare against the GauSwastha regression head. GauSwastha's production weight estimator is a learned model with no explicit geometry. If BosWeigh's formula-based pipeline ever beats it on the same validation set, it will be because the geometry is doing real work — and that's worth knowing either way.
Even if BosWeigh never beats an end-to-end learned model on accuracy, it's useful as an explainable weight estimate — a farmer and a vet can see where the length and girth came from, argue about them, and retake the photo. That matters in a domain where a black-box number is a hard sell at 6am in a village shed.